By Anna Lau, PhD, Medical Writer
From 1975 to 2005, the average cost to develop a single new drug rose from $100 million to $1.3 billion (adjusted to year 2000 US dollars). At least 90% of this staggering cost is consumed by executing phase 3 clinical studies. But as phase 3 studies have gotten larger, longer, and more complex, fewer patients meet the eligibility criteria and more participants quit mid-study. In addition, about 70%-75% of drugs fail this phase of development because of safety concerns, lack of efficacy, or other reasons. No wonder there’s frustration!
Is it time to change the way phase 3 studies are conducted?
Conventional phase 3 studies are usually randomized and controlled. The salient study design feature is the equal probability that participants will be randomized to intervention or control. This randomization scheme minimizes selection bias more effectively than any other study design element, making it the “gold standard” of study designs.
__________
Although phase 3 randomized studies assume a priori that the null hypothesis is true (that the intervention and the control are equal), patients generally assume that the intervention is superior to control. What do you think is the basis for this bias that “new is better”?
__________
But this randomization element is precisely why up to 31% of patients decline to participate in clinical studies. Clinical investigators could opt for a 2:1 randomization ratio, but this would only increase the odds of—not guarantee—assignment to the intervention arm. Also, if a two-arm randomized controlled study shows no advantage of intervention over control, then it’s back to the drawing board to plan a brand new study protocol, a process that could take years. What’s the alternative?
Enter the outcome-adaptive randomization study design.
With outcome-adaptive randomization, randomization probabilities can be adjusted based on experimental results already observed—in other words, patients are more likely to be assigned to the more effective study arm (if there is one) over the course of the study (Figure 1).
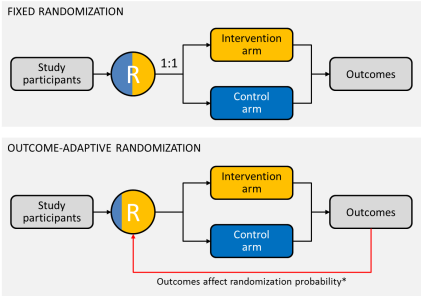 Figure 1. Diagrammatic representation of fixed and outcome-adaptive randomization schemes. *Probability of assignment to intervention arm = [(probability that intervention is superior)a] ÷ [(probability that intervention is superior)a + (probability that control is superior)a], where a is a positive tuning parameter that controls the degree of imbalance (a is usually a value between 0 and 1; when a = 0, randomization is fixed at 1:1; when a = 1, the probability of randomization to intervention equals the probability that intervention is superior). Whew! That’s enough math.
Figure 1. Diagrammatic representation of fixed and outcome-adaptive randomization schemes. *Probability of assignment to intervention arm = [(probability that intervention is superior)a] ÷ [(probability that intervention is superior)a + (probability that control is superior)a], where a is a positive tuning parameter that controls the degree of imbalance (a is usually a value between 0 and 1; when a = 0, randomization is fixed at 1:1; when a = 1, the probability of randomization to intervention equals the probability that intervention is superior). Whew! That’s enough math.

Outcome-adaptive randomization study design is based on Bayesian analysis, an inductive approach that uses observed outcomes to formulate conclusions about the intervention. For example: Given the observed experiment results, what is the probability that intervention is superior to control? In contrast, a classical statistical analysis uses deductive inference to determine the probability of an observed outcome assuming that the null hypothesis is true. For example: What is the probability of observing these experimental results, if the intervention and the control are equally effective?
So, outcome-adaptive randomization must be better for patients, right?
Short answer: not always.
In a recent report, Korn and Friedlin used simulations to compare fixed balanced randomization (1:1) and outcome-adaptive randomization. The authors assumed: (1) there are two study arms, one of which is a control arm; (2) outcomes are short-term; (3) outcomes are binary (response vs. no response); and (4) patient accrual rates are not affected by study design. The authors determined the required sample sizes, and average proportions of patients with response to treatment (responders) and numbers of patients without response to treatment (nonresponders), assuming a 40% response rate with intervention vs. 20% response rate with control. They found that the adaptive design did not markedly change the proportion of responders but increased the number of nonresponders, compared with 1:1 randomization design. The authors found outcome-adaptive randomization to be “inferior” to 1:1 randomization and to offer “modest-to-no benefits to the patients.”
What?!
These results may seem surprising, but there are general downsides to outcome-adaptive randomization:
- Adaptive randomization studies are logistically complicated. For instance, they require that treatment assignment be linked to outcome data.
- Early results from the study could bias enrollment into the study. For instance, would patients enroll in a study in which control looks better than intervention?
- If control does outperform intervention, the study sponsor might end up funding a study in which the majority of patients are assigned to the control arm.
But there must be upsides! And indeed there are.
First, the assumptions made by Korn and Friedlin (only two study arms, patient accrual rates not affected by study design, etc), limit the applicability of their conclusions to situations outside the described scenarios (full description of limitations here).
Further, the advantages of this design are highlighted in studies with more than two arms (eg, multiple regimens, doses, or dosing schedules). In these, a superior intervention could be identified without enrolling equal numbers of patients in each arm. This could allow shorter clinical studies that evaluate more interventions. And if one arm performs poorly, randomization to that arm could be limited or the arm could be dropped altogether, depending on the inferiority cutoffs built into the study design. Furthermore, outcome-adaptive randomization combined with biomarker studies at baseline can potentially identify relationships between response and biomarker status, which cannot be achieved with fixed randomization.
Take the phase 2 BATTLE study, the first completed prospective, outcome-adaptive, randomized study in late-stage non-small cell lung cancer. Patients underwent tumor biomarker profiling before randomization to one of four treatment arms: erlotinib, sorafenib, vandetanib, and erlotinib + bexarotene. Subsequent randomization considered the responses of previously randomized patients with the same biomarker profile. Historically, the disease control rate (DCR) at 8 weeks for this patient population is about 30%. But in BATTLE, overall DCR was 46%. Even better, the study showed that biomarker profile correlates with response to specific treatments. This was important because, at the time, biomarkers for those drugs had not been validated. Overall, BATTLE demonstrated the possibility and feasibility of personalizing treatment to patient.
Right now, the phase 2 I-SPY 2 study is trying to do for breast cancer what the BATTLE study did for lung cancer. In I-SPY 2, newly diagnosed patients with locally advanced breast cancer will undergo biomarker profiling before randomization to one of up to 12 neoadjuvant therapy regimens. The study design will allow clinical investigators to graduate (move forward in development when outcome fulfills a Bayesian prediction), drop, or add drugs seamlessly throughout the course of the study without terminating the study and starting over. This could drastically reduce the time it takes the study to move from one drug to another.
Should outcome-adaptive randomization become the new “gold standard”?
Short answer: Not quite yet. But the potential advantages and disadvantages of these study designs must be recognized. Based on the attention that the BATTLE and I-SPY 2 studies have gotten, though, expect to see more outcome-adaptive randomized studies in the future. The potential for shorter clinical studies evaluating more than one intervention at a time could mean considerable cost and time savings in drug development.
